Table of contents > Looping/iterating in Nodezator
In text-based programming with Python, we usually perform looping using a for-loop or while-loop, and with good reason, since they are practical and very readable.
On the other hand, in a node-based programming application like Nodezator, whose graphs represent chained function calls, looping is also performed with calls to functions.
Many Python built-in and standard library functions that help with looping/iteration are available by default in Nodezator.
Perhaps chief among them is the map() node, which represents Python's map() built-in. With it, you can apply a given callable to items in one or more iterable objects. For instance, if you want to loop over numbers in a range object, producing a list containing numbers which are the double of the numbers in the range, you can do it like so:
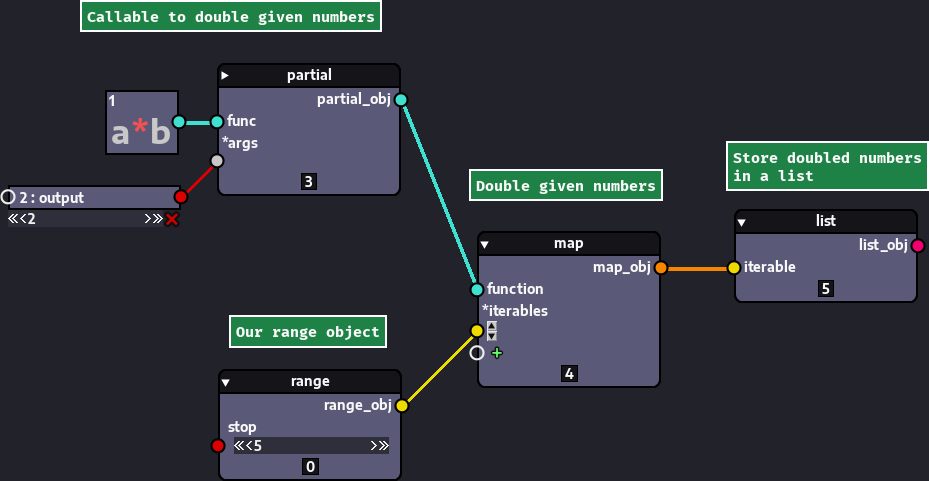
In the image above we begin by creating a callable that returns the given numbers multiplied by 2, by passing the a*b node in callable mode to the partial() node along with the number 2 as one of the arguments. Next, we create a range node to produce our range object. Then, we pass the callable used to double numbers and the range object to the map() node. And finally, we pass the resulting map object to the list() node.
Note that, since we are interested in the outputs of our callable that doubles numbers, we must build a collection to hold these numbers, regardless of whether we use a list, set, tuple or other kind of collection.
This is so because many of the functions used to loop in Python are lazily evaluated. Their underlying operations are only carried out when needed, that is, when building a collection or when being iterated over in a for-loop. Just passing the callable that doubles and the range to map() is not enough to trigger the execution of the callable that doubles the range items. This is why we need to connect our map node to the list() node for the doubled numbers to be produced.
However, what if you were not interested in the outputs produced, just wanted an action to be carried out many times over? You could of course use a list() node as well, or any other node producing a collection, but at the end it would produce a needless collection of meaningless values. For cases like this, Nodezator offers an app-defined node that emulates an empty for-loop for you, the for_item_in_obj_pass() node. As we just said, being iterated over in a for-loop is one way to carry out the underlying operations of a lazily evaluated object (like the map object returned by our map node). The source code of this node, as can be inferred by its name, is roughly equivalent to this:
def for_item_in_obj_pass(obj):
for item in obj:
passJust connect your map node to it and it will trigger the execution of the underlying operation in your map() node. For instance, to print each item in a range in its own line, you can do this:
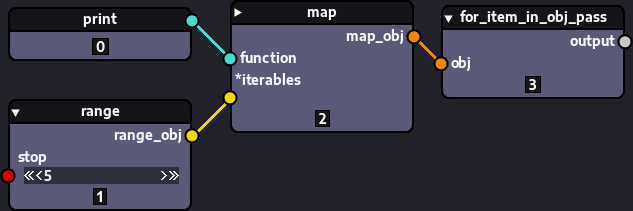
As we said before, you could also have connected the map() node to a list() node or other collection, but it would have created and populated a collection with the output of the calls. Since the calls performed in our map object are calls to the print() function, which always returns None, you would end up with a useless collection full of None objects.
The for_item_in_obj_pass() node on the other hand ignores the items. Its only purpose is to trigger the execution.
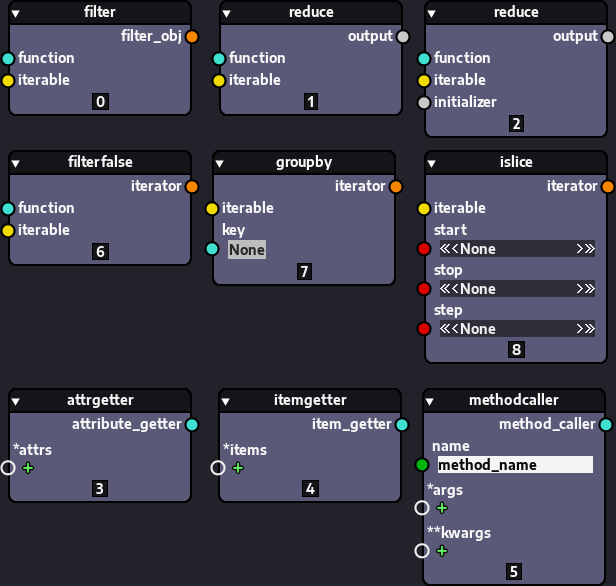
Applying callables to items isn't the only useful way of looping/iterating. You may also want to filter, group, slice, reduce to a single item and do many other things with items. To perform or assist in those things and many more, Nodezator provides many other nodes by default, like the built-in filter() and functions from the standard library modules itertools, functools and operator.
It is no coincidence that this section has the same title of a section from the chapter on conditional execution. Just like for conditional execution, subgraphs (group nodes) are also a crucial missing piece for looping in Nodezator.
The print() function passed to the map() node in this chapter represents an atomic operation: printing a value. The callable used to double numbers was relatively simple as well, and required only 02 nodes, the a+b node and the partial() node. However, in practice, callables we would apply to items using map() or use in other kinds of iteration with other nodes other than map() will often be the result of the combination of many nodes. This is precisely why we use a node-based interface to program, so we can combine different nodes to achieve a certain result.
That's where subgraphs (similar to group nodes in Blender3D) are useful. As said in the chapter about conditional execution, this is something that will still take a while to land on Nodezator, but is something indispensable in order to tackle more complex looping/iteration in Nodezator.
Once subgraphs/group nodes are implemented, whenever we need to represent a complex operation that requires the usage of multiple nodes, all we'll have to do is create the nodes, group them together, select which inputs and outputs we want to expose, and use the resulting group node as demonstrated in our examples in this chapther: in callable mode, and with help of nodes like map() and many others.